Variables Aléatoires
Cheatsheet Content
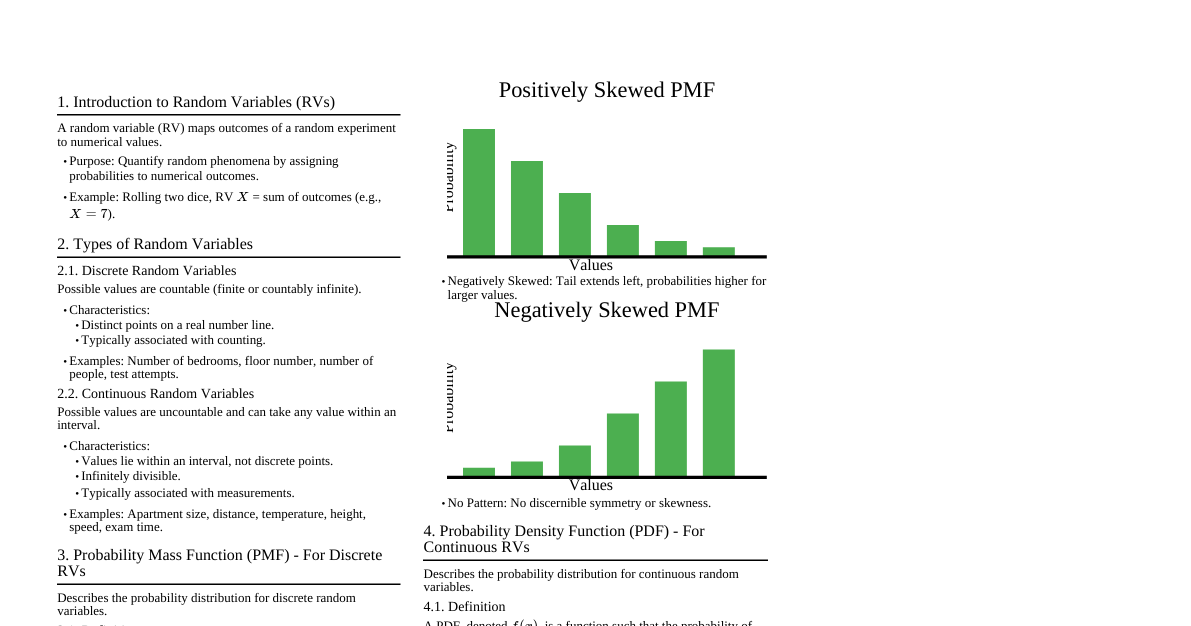
### Introduction aux Variables Aléatoires Une variable aléatoire est une fonction qui associe un nombre réel à chaque résultat d'une expérience aléatoire. Elles sont fondamentales en probabilités et statistiques pour modéliser des phénomènes incertains. ### Variable Aléatoire Discrète Une variable aléatoire discrète (VAD) est une variable dont l'ensemble des valeurs possibles est fini ou dénombrable. Les valeurs sont généralement des nombres entiers et sont comptables. #### Caractéristiques - **Valeurs:** Nombres entiers, comptables (ex: 0, 1, 2, 3...). - **Représentation graphique:** Diagramme en bâtons ou histogramme de fréquences. - **Exemples:** Nombre de faces en lançant une pièce 10 fois, nombre de voitures passant un péage en une heure, nombre d'enfants dans une famille. #### Fonction de Masse de Probabilité (FMP) La FMP, notée $P(X=x)$ ou $f(x)$, donne la probabilité que la variable aléatoire $X$ prenne une valeur spécifique $x$. - Condition 1: $0 \le P(X=x) \le 1$ pour toutes les valeurs de $x$. - Condition 2: $\sum_{x} P(X=x) = 1$ (la somme des probabilités de toutes les valeurs possibles est égale à 1). #### Fonction de Répartition (CDF) La CDF, notée $F(x)$, donne la probabilité que la variable aléatoire $X$ prenne une valeur inférieure ou égale à $x$. $$F(x) = P(X \le x) = \sum_{t \le x} P(X=t)$$ - Propriétés: - $0 \le F(x) \le 1$ - $F(x)$ est une fonction non-décroissante. - $\lim_{x \to -\infty} F(x) = 0$ - $\lim_{x \to +\infty} F(x) = 1$ - $P(a ### Variable Aléatoire Continue Une variable aléatoire continue (VAC) est une variable dont l'ensemble des valeurs possibles est un intervalle (ou une union d'intervalles) sur la droite réelle. Les valeurs peuvent être n'importe quel nombre réel dans cet intervalle. #### Caractéristiques - **Valeurs:** Nombres réels, non comptables (ex: tailles, poids, temps, températures). - **Probabilité ponctuelle:** Pour une VAC, la probabilité qu'elle prenne une valeur *exacte* est toujours nulle, $P(X=x) = 0$. On ne peut calculer des probabilités que sur des intervalles. - **Représentation graphique:** Courbe de densité de probabilité. - **Exemples:** La taille d'une personne, le temps d'attente à un arrêt de bus, la température d'une pièce. #### Fonction de Densité de Probabilité (FDP) La FDP, notée $f(x)$, décrit la probabilité relative qu'une VAC prenne une valeur donnée. Ce n'est PAS une probabilité directe. - Condition 1: $f(x) \ge 0$ pour toutes les valeurs de $x$. - Condition 2: $\int_{-\infty}^{\infty} f(x) dx = 1$ (l'aire totale sous la courbe est égale à 1). - La probabilité que $X$ se situe dans un intervalle $[a, b]$ est l'aire sous la FDP entre $a$ et $b$: $$P(a \le X \le b) = \int_{a}^{b} f(x) dx$$ #### Fonction de Répartition (CDF) La CDF, notée $F(x)$, donne la probabilité que la variable aléatoire $X$ prenne une valeur inférieure ou égale à $x$. $$F(x) = P(X \le x) = \int_{-\infty}^{x} f(t) dt$$ - Propriétés: - $0 \le F(x) \le 1$ - $F(x)$ est une fonction non-décroissante. - $\lim_{x \to -\infty} F(x) = 0$ - $\lim_{x \to +\infty} F(x) = 1$ - $P(a 0$. ($\Gamma(k)$ est la fonction Gamma). - $E[X] = k\theta$ - $Var(X) = k\theta^2$ ##### Loi Bêta Utilisée pour modéliser des probabilités ou des proportions, souvent sur l'intervalle [0, 1]. - $X \sim Beta(\alpha, \beta)$ - FDP: $f(x) = \frac{x^{\alpha-1}(1-x)^{\beta-1}}{B(\alpha, \beta)}$ pour $0 \le x \le 1$. ($B(\alpha, \beta)$ est la fonction Bêta). - $E[X] = \frac{\alpha}{\alpha+\beta}$ - $Var(X) = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}$ ### Comparaison entre Variables Aléatoires Discrètes et Continues | Caractéristique | Variable Aléatoire Discrète (VAD) | Variable Aléatoire Continue (VAC) | |-----------------------|---------------------------------------------------------------------|-------------------------------------------------------------------| | **Valeurs possibles** | Fini ou dénombrable (nombres entiers, comptables) | Infini et non dénombrable (nombres réels, mesurables) | | **Probabilité $P(X=x)$** | Peut être non nulle | Toujours nulle ($P(X=x) = 0$) | | **Fonction clé** | Fonction de Masse de Probabilité (FMP) $P(X=x)$ | Fonction de Densité de Probabilité (FDP) $f(x)$ | | **Calcul des probabilités** | Sommation de $P(X=x)$ | Intégration de $f(x)$ | | **Fonction de Répartition $F(x)$** | Fonction en escalier (sauts aux valeurs discrètes) | Fonction continue et lisse | | **Espérance $E[X]$** | $\sum x \cdot P(X=x)$ | $\int x \cdot f(x) dx$ | | **Variance $Var(X)$** | $\sum (x - E[X])^2 \cdot P(X=x)$ | $\int (x - E[X])^2 \cdot f(x) dx$ | | **Exemples** | Nombre de défauts, nombre de têtes, nombre de clients | Taille, poids, temps, température, tension électrique | ### Théorèmes Limites Importants #### Loi des Grands Nombres (LGN) Décrit le comportement à long terme de la moyenne d'une suite de variables aléatoires. Si $X_1, X_2, ..., X_n$ sont des variables aléatoires indépendantes et identiquement distribuées (iid) avec une espérance $E[X_i] = \mu ### Transformations de Variables Aléatoires Souvent, on s'intéresse à une fonction d'une variable aléatoire, $Y = g(X)$. #### Pour une VAD Si $Y = g(X)$, alors $E[Y] = E[g(X)] = \sum_x g(x) P(X=x)$. #### Pour une VAC Si $Y = g(X)$, alors $E[Y] = E[g(X)] = \int_{-\infty}^{\infty} g(x) f_X(x) dx$. #### Changement de Variable (pour VAC) Si $Y = g(X)$ est une fonction monotone et dérivable. La FDP de $Y$ est donnée par: $$f_Y(y) = f_X(g^{-1}(y)) \left| \frac{d}{dy} g^{-1}(y) \right|$$ Où $g^{-1}(y)$ est la fonction inverse de $g(x)$. #### Propriétés de l'Espérance et de la Variance - $E[c] = c$ (où $c$ est une constante) - $E[aX + b] = aE[X] + b$ - $E[X+Y] = E[X] + E[Y]$ (toujours vrai, même si $X$ et $Y$ ne sont pas indépendantes) - $Var(c) = 0$ - $Var(aX + b) = a^2 Var(X)$ - $Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)$ - Si $X$ et $Y$ sont indépendantes, $Var(X+Y) = Var(X) + Var(Y)$ (car $Cov(X,Y)=0$) - $Cov(X,Y) = E[(X-E[X])(Y-E[Y])] = E[XY] - E[X]E[Y]$ - $Corr(X,Y) = \frac{Cov(X,Y)}{\sigma_X \sigma_Y}$ (coefficient de corrélation) ### Moments d'une Variable Aléatoire Les moments sont des mesures qui caractérisent la forme d'une distribution de probabilité. #### Moment d'ordre $k$ autour de l'origine $E[X^k]$ Pour VAD: $\sum_x x^k P(X=x)$ Pour VAC: $\int_{-\infty}^{\infty} x^k f(x) dx$ - Le premier moment ($k=1$) est l'espérance $E[X]$. #### Moment centré d'ordre $k$ $E[(X - E[X])^k]$ - Le premier moment centré ($k=1$) est $E[X-E[X]] = E[X] - E[X] = 0$. - Le deuxième moment centré ($k=2$) est la variance $Var(X)$. #### Asymétrie (Skewness) Mesure le degré d'asymétrie de la distribution. $$\gamma_1 = E\left[\left(\frac{X - \mu}{\sigma}\right)^3\right] = \frac{E[(X-\mu)^3]}{\sigma^3}$$ - $\gamma_1 = 0$: distribution symétrique (ex: Normale). - $\gamma_1 > 0$: queue de distribution plus longue à droite (asymétrie positive). - $\gamma_1 0$: Leptokurtique (distribution plus pointue avec des queues plus épaisses que la Normale). - $\gamma_2 ### Distributions Jointes (Variables Aléatoires Multiples) Ces concepts s'étendent aux situations où l'on considère plusieurs variables aléatoires simultanément. #### Variables Aléatoires Discrètes Multiples - **Fonction de Masse de Probabilité Jointe (FMPJ):** $P(X=x, Y=y)$ - $\sum_x \sum_y P(X=x, Y=y) = 1$ - **FMP Marginale:** - $P(X=x) = \sum_y P(X=x, Y=y)$ - $P(Y=y) = \sum_x P(X=x, Y=y)$ - **FMP Conditionnelle:** - $P(X=x | Y=y) = \frac{P(X=x, Y=y)}{P(Y=y)}$ si $P(Y=y) > 0$ - **Indépendance:** $X$ et $Y$ sont indépendantes si $P(X=x, Y=y) = P(X=x) P(Y=y)$ pour tout $x, y$. #### Variables Aléatoires Continues Multiples - **Fonction de Densité de Probabilité Jointe (FDPJ):** $f(x, y)$ - $\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f(x, y) dx dy = 1$ - **FDP Marginale:** - $f_X(x) = \int_{-\infty}^{\infty} f(x, y) dy$ - $f_Y(y) = \int_{-\infty}^{\infty} f(x, y) dx$ - **FDP Conditionnelle:** - $f_{X|Y}(x|y) = \frac{f(x, y)}{f_Y(y)}$ si $f_Y(y) > 0$ - **Indépendance:** $X$ et $Y$ sont indépendantes si $f(x, y) = f_X(x) f_Y(y)$ pour tout $x, y$. #### Covariance et Corrélation - **Covariance:** Mesure la tendance de $X$ et $Y$ à varier ensemble. - $Cov(X,Y) = E[(X-E[X])(Y-E[Y])] = E[XY] - E[X]E[Y]$ - **Coefficient de Corrélation de Pearson:** Mesure la force et la direction de la relation linéaire entre $X$ et $Y$. - $\rho_{XY} = \frac{Cov(X,Y)}{\sigma_X \sigma_Y}$ - $-1 \le \rho_{XY} \le 1$ - $\rho_{XY} = 0$ implique l'absence de relation linéaire (mais pas nécessairement d'indépendance). - Si $X$ et $Y$ sont indépendantes, alors $Cov(X,Y)=0$ et $\rho_{XY}=0$. La réciproque n'est pas toujours vraie. ### Fonction Génératrice des Moments (FGM) La FGM d'une variable aléatoire $X$, notée $M_X(t)$, est définie par $M_X(t) = E[e^{tX}]$, pour toutes les valeurs de $t$ pour lesquelles l'espérance existe. #### Pour une VAD $$M_X(t) = \sum_x e^{tx} P(X=x)$$ #### Pour une VAC $$M_X(t) = \int_{-\infty}^{\infty} e^{tx} f(x) dx$$ #### Propriétés de la FGM - **Génération des moments:** Les moments d'ordre $k$ peuvent être obtenus en dérivant la FGM $k$ fois par rapport à $t$ et en évaluant à $t=0$. - $E[X^k] = M_X^{(k)}(0) = \left. \frac{d^k}{dt^k} M_X(t) \right|_{t=0}$ - $E[X] = M_X'(0)$ - $E[X^2] = M_X''(0)$, donc $Var(X) = M_X''(0) - (M_X'(0))^2$ - **Unicité:** Si deux variables aléatoires ont la même FGM, alors elles ont la même distribution de probabilité. - **Somme de variables indépendantes:** Si $X_1, X_2, ..., X_n$ sont des variables aléatoires indépendantes, alors la FGM de leur somme $S_n = \sum_{i=1}^n X_i$ est le produit de leurs FGMs individuelles: - $M_{S_n}(t) = \prod_{i=1}^n M_{X_i}(t)$ - **Transformations linéaires:** $M_{aX+b}(t) = e^{bt} M_X(at)$ #### Exemples de FGM - **Bernoulli($p$):** $M_X(t) = (1-p) + pe^t$ - **Binomiale($n, p$):** $M_X(t) = ((1-p) + pe^t)^n$ - **Poisson($\lambda$):** $M_X(t) = e^{\lambda(e^t-1)}$ - **Uniforme($a, b$):** $M_X(t) = \frac{e^{tb} - e^{ta}}{t(b-a)}$ - **Exponentielle($\lambda$):** $M_X(t) = \frac{\lambda}{\lambda-t}$ pour $t ### Fonction Caractéristique (FC) La fonction caractéristique d'une variable aléatoire $X$, notée $\phi_X(t)$, est définie par $\phi_X(t) = E[e^{itX}]$, où $i$ est l'unité imaginaire ($i^2 = -1$). Elle est similaire à la FGM mais existe toujours. #### Pour une VAD $$\phi_X(t) = \sum_x e^{itx} P(X=x)$$ #### Pour une VAC $$\phi_X(t) = \int_{-\infty}^{\infty} e^{itx} f(x) dx$$ #### Propriétés de la FC - **Existence:** La fonction caractéristique existe toujours pour toute variable aléatoire. - **Génération des moments:** - $E[X^k] = \frac{\phi_X^{(k)}(0)}{i^k}$ - **Unicité:** Si deux variables aléatoires ont la même FC, alors elles ont la même distribution. - **Somme de variables indépendantes:** Si $X_1, ..., X_n$ sont indépendantes, $\phi_{\sum X_i}(t) = \prod \phi_{X_i}(t)$. - **Transformations linéaires:** $\phi_{aX+b}(t) = e^{itb} \phi_X(at)$. ### Inégalités Importantes Ces inégalités fournissent des bornes sur les probabilités ou les moments sans connaître la distribution exacte. #### Inégalité de Markov Pour une variable aléatoire $X \ge 0$ et $a > 0$: $$P(X \ge a) \le \frac{E[X]}{a}$$ #### Inégalité de Chebyshev Pour une variable aléatoire $X$ avec espérance $\mu$ et variance $\sigma^2 0$: $$P(|X - \mu| \ge k\sigma) \le \frac{1}{k^2}$$ Ou de manière équivalente: $$P(|X - \mu| \ge \epsilon) \le \frac{Var(X)}{\epsilon^2}$$ Cette inégalité montre que la probabilité qu'une variable aléatoire s'éloigne de sa moyenne diminue rapidement avec l'écart. C'est la base de la Loi Faible des Grands Nombres. #### Inégalité de Jensen Si $g$ est une fonction convexe et $X$ est une variable aléatoire: $$E[g(X)] \ge g(E[X])$$ Si $g$ est concave: $$E[g(X)] \le g(E[X])$$ ### Estimation de Paramètres En statistique inférentielle, on utilise des échantillons pour estimer les paramètres inconnus d'une population. #### Estimateur du Maximum de Vraisemblance (EMV) L'EMV est un estimateur qui maximise la fonction de vraisemblance, $L(\theta|\mathbf{x})$, qui est la probabilité (ou densité de probabilité) d'observer les données $\mathbf{x}$ étant donné le paramètre $\theta$. - Pour VAD: $L(\theta|\mathbf{x}) = P(X_1=x_1, ..., X_n=x_n | \theta) = \prod_{i=1}^n P(X_i=x_i | \theta)$ - Pour VAC: $L(\theta|\mathbf{x}) = f(x_1, ..., x_n | \theta) = \prod_{i=1}^n f(x_i | \theta)$ Souvent, on maximise le log-vraisemblance, $\ln L(\theta|\mathbf{x})$, car c'est plus simple à dériver. #### Estimateur des Moindres Carrés (EMC) Utilisé principalement dans la régression linéaire, l'EMC minimise la somme des carrés des erreurs entre les valeurs observées et les valeurs prédites par le modèle. #### Propriétés des Estimateurs - **Biais:** $Biais(\hat{\theta}) = E[\hat{\theta}] - \theta$. Un estimateur est sans biais si $Biais(\hat{\theta}) = 0$. - **Variance:** $Var(\hat{\theta})$. Un estimateur est d'autant plus efficace que sa variance est faible. - **Erreur Quadratique Moyenne (EQM):** $EQM(\hat{\theta}) = E[(\hat{\theta} - \theta)^2] = Var(\hat{\theta}) + (Biais(\hat{\theta}))^2$. - **Consistance:** Un estimateur est consistent si, lorsque la taille de l'échantillon $n$ tend vers l'infini, l'estimateur converge en probabilité vers le vrai paramètre $\theta$. - **Efficacité:** Un estimateur est efficace s'il atteint la borne de Cramér-Rao, c'est-à-dire s'il a la variance minimale possible pour un estimateur sans biais. #### Intervalle de Confiance Un intervalle de confiance à $(1-\alpha)100\%$ pour un paramètre $\theta$ est un intervalle $[L, U]$ tel que $P(L \le \theta \le U) = 1-\alpha$. Pour une moyenne $\mu$ d'une population normale (ou grand échantillon par TCL): - Si $\sigma$ est connu: $\bar{X} \pm z_{\alpha/2} \frac{\sigma}{\sqrt{n}}$ - Si $\sigma$ est inconnu (et $n$ petit): $\bar{X} \pm t_{\alpha/2, n-1} \frac{S}{\sqrt{n}}$ Où $z_{\alpha/2}$ est le quantile de la loi normale standard et $t_{\alpha/2, n-1}$ est le quantile de la loi de Student avec $n-1$ degrés de liberté. ### Tests d'Hypothèses Un test d'hypothèse est une procédure formelle pour décider si une hypothèse concernant un paramètre de population est plausible, basée sur des données d'échantillon. #### Étapes Générales 1. **Formuler les hypothèses:** - **Hypothèse Nulle ($H_0$):** L'hypothèse que l'on cherche à réfuter (ex: $\mu = \mu_0$). - **Hypothèse Alternative ($H_1$ ou $H_a$):** L'hypothèse que l'on accepte si $H_0$ est rejetée (ex: $\mu \ne \mu_0$, $\mu > \mu_0$, ou $\mu \alpha$, ne pas rejeter $H_0$. #### Tests Courants ##### Test Z (pour la moyenne, $\sigma$ connu) - Statistique de test: $Z = \frac{\bar{X} - \mu_0}{\sigma/\sqrt{n}}$ - Utilisation: Pour tester des hypothèses sur la moyenne d'une population lorsque l'écart-type de la population est connu, ou pour de grands échantillons par le TCL. ##### Test t de Student (pour la moyenne, $\sigma$ inconnu) - Statistique de test: $T = \frac{\bar{X} - \mu_0}{S/\sqrt{n}}$ - Utilisation: Pour tester des hypothèses sur la moyenne d'une population lorsque l'écart-type de la population est inconnu, surtout pour de petits échantillons. La statistique $T$ suit une loi de Student avec $n-1$ degrés de liberté. ##### Test du Chi-deux ($\chi^2$) - **Test d'ajustement:** Pour vérifier si une distribution observée correspond à une distribution théorique attendue. - **Test d'indépendance:** Pour vérifier si deux variables catégorielles sont indépendantes. - **Statistique de test:** $\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}$ - $O_i$: Fréquence observée dans la catégorie $i$. - $E_i$: Fréquence attendue dans la catégorie $i$ sous $H_0$. ### Régression Linéaire Simple Modélise la relation linéaire entre une variable dépendante $Y$ et une variable indépendante $X$. #### Modèle $$Y_i = \beta_0 + \beta_1 X_i + \epsilon_i$$ - $Y_i$: Variable dépendante observée. - $X_i$: Variable indépendante observée. - $\beta_0$: Ordonnée à l'origine (intercept). - $\beta_1$: Pente de la droite de régression. - $\epsilon_i$: Terme d'erreur aléatoire, généralement supposé suivre $N(0, \sigma^2)$ et être indépendant. #### Estimateurs des Moindres Carrés Ordinaires (MCO) Les estimateurs de $\beta_0$ et $\beta_1$ qui minimisent la somme des carrés des résidus, $\sum (Y_i - \hat{Y}_i)^2$. - $\hat{\beta}_1 = \frac{\sum (X_i - \bar{X})(Y_i - \bar{Y})}{\sum (X_i - \bar{X})^2} = \frac{Cov(X,Y)}{Var(X)}$ - $\hat{\beta}_0 = \bar{Y} - \hat{\beta}_1 \bar{X}$ - La droite de régression ajustée est $\hat{Y} = \hat{\beta}_0 + \hat{\beta}_1 X$. #### Coefficient de Détermination ($R^2$) Mesure la proportion de la variance de la variable dépendante qui est expliquée par le modèle de régression. $$R^2 = 1 - \frac{SSE}{SST} = \frac{SSR}{SST}$$ - $SSE = \sum (Y_i - \hat{Y}_i)^2$ (Somme des Carrés des Erreurs) - $SST = \sum (Y_i - \bar{Y})^2$ (Somme Totale des Carrés) - $SSR = \sum (\hat{Y}_i - \bar{Y})^2$ (Somme des Carrés de la Régression) - $0 \le R^2 \le 1$. Un $R^2$ proche de 1 indique un bon ajustement du modèle. ### Processus Stochastiques Une collection de variables aléatoires indexées par le temps ou l'espace. #### Chaînes de Markov Un processus stochastique où la probabilité de passer à un état futur ne dépend que de l'état actuel et non des états passés (propriété de Markov). - **Matrice de transition:** $P = (p_{ij})$, où $p_{ij}$ est la probabilité de passer de l'état $i$ à l'état $j$. - **Distribution stationnaire:** Une distribution de probabilité $\pi$ telle que $\pi P = \pi$. #### Processus de Poisson Décrit le nombre d'événements se produisant dans un intervalle de temps donné, si les événements se produisent avec un taux moyen constant et indépendamment les uns des autres. - **Nombre d'événements:** Suit une loi de Poisson. - **Temps entre événements:** Suit une loi exponentielle.