Advanced Data Structures
Cheatsheet Content
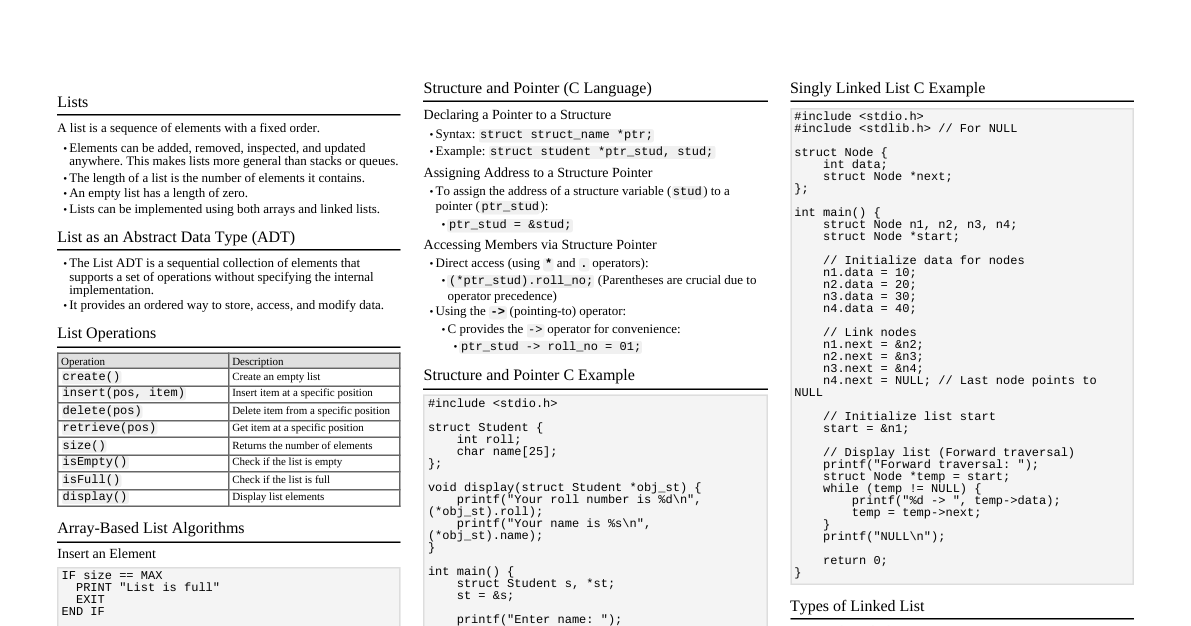
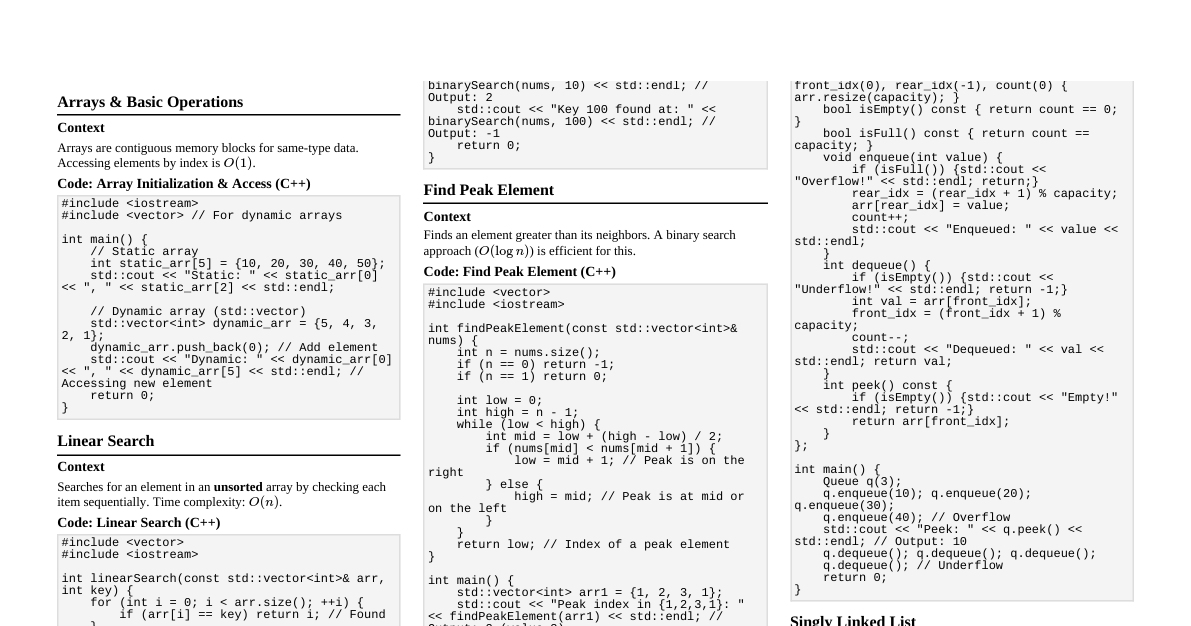
### Hash Tables - **Definition:** Data structure that maps keys to values using a hash function. Provides average $O(1)$ time complexity for insertion, deletion, and lookup. - **Components:** - **Hash Function:** Converts a key into an index in the array. - **Array (Bucket Array):** Stores key-value pairs. - **Collision Resolution:** Strategies to handle when two different keys hash to the same index. - **Collision Resolution Techniques:** - **Separate Chaining:** Each array slot points to a linked list (or another data structure) of key-value pairs that hash to that slot. - **Open Addressing:** All elements are stored directly in the hash table array. When a collision occurs, probe for an empty slot. - **Linear Probing:** Search for the next empty slot sequentially. - **Quadratic Probing:** Search for the next empty slot using a quadratic function. - **Double Hashing:** Use a second hash function to determine the step size for probing. - **Load Factor ($\alpha$):** $\alpha = \text{number of entries} / \text{number of buckets}$. - If $\alpha$ gets too high, performance degrades. Resizing (rehash all elements into a larger table) is often required. - **Applications:** Symbol tables, database indexing, caches, sets. ### Trees #### Binary Search Trees (BST) - **Properties:** Left child ### Heaps - **Definition:** A complete binary tree that satisfies the heap property. - **Heap Property:** - **Min-Heap:** Parent node value $\le$ child node values. - **Max-Heap:** Parent node value $\ge$ child node values. - **Operations:** - **`insert`:** Add to end, then `heapify-up` ($O(\log n)$). - **`deleteMin/Max`:** Replace root with last element, `heapify-down` ($O(\log n)$). - **`buildHeap`:** From an array, $O(n)$. - **Applications:** Priority queues, Heap Sort. ### Graphs - **Representation:** - **Adjacency Matrix:** $A[i][j]=1$ if edge $(i, j)$ exists, else 0. $O(V^2)$ space. Good for dense graphs. - **Adjacency List:** Array of lists, where `adj[i]` contains neighbors of vertex $i$. $O(V+E)$ space. Good for sparse graphs. - **Traversal Algorithms:** - **Breadth-First Search (BFS):** Explores level by level. Uses a queue. Finds shortest path in unweighted graphs. $O(V+E)$. - **Depth-First Search (DFS):** Explores as far as possible along each branch before backtracking. Uses a stack (or recursion). $O(V+E)$. - **Shortest Path Algorithms:** - **Dijkstra's Algorithm:** Finds shortest paths from a single source to all other vertices in a graph with non-negative edge weights. Uses a min-priority queue. $O(E \log V)$ or $O(E+V \log V)$ with Fibonacci heap. - **Bellman-Ford Algorithm:** Finds shortest paths from a single source to all other vertices, handles negative edge weights. Detects negative cycles. $O(VE)$. - **Floyd-Warshall Algorithm:** Finds shortest paths between all pairs of vertices. $O(V^3)$. - **Minimum Spanning Tree (MST):** A subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight. - **Prim's Algorithm:** Builds MST by adding edges to a growing tree. Uses a min-priority queue. $O(E \log V)$ or $O(E+V \log V)$. - **Kruskal's Algorithm:** Builds MST by adding edges in increasing order of weight, avoiding cycles. Uses a Disjoint Set Union (DSU) data structure. $O(E \log E)$ or $O(E \log V)$. ### Tries (Prefix Trees) - **Definition:** Tree-like data structure used to store a dynamic set of strings where the nodes represent characters and paths represent words. - **Properties:** - Each node stores a character. - Children of a node are stored in an array or hash map. - A special flag (e.g., `isEndOfWord`) indicates if a node completes a word. - **Operations:** - **`insert`:** Traverse the trie, adding nodes for new characters. Mark the end node. $O(L)$ where $L$ is word length. - **`search`:** Traverse based on characters. Check `isEndOfWord` flag. $O(L)$. - **`startsWith` (prefix search):** Similar to search, but no need to check `isEndOfWord`. $O(L)$. - **Applications:** Autocomplete, spell checkers, IP routing, dictionary search. ### Segment Trees - **Definition:** A tree data structure used for storing information about intervals or segments. It allows querying for information about a range (e.g., sum, min, max) in $O(\log n)$ time and updating a point or range in $O(\log n)$ time. - **Construction:** Build a binary tree where each leaf node represents an element of the input array, and each internal node represents an aggregation of its children's ranges. $O(n)$ time. - **Operations:** - **`query(range)`:** Recursively traverse the tree, combine results from overlapping nodes. $O(\log n)$. - **`update(index, value)`:** Update leaf node, then propagate changes up to parent nodes. $O(\log n)$. - **Lazy Propagation:** Optimization for range updates. Instead of updating all elements in a range immediately, mark nodes as "lazy" and apply updates only when necessary during a query. - **Applications:** Range Minimum/Maximum Query (RMQ), Range Sum Query (RSQ), competitive programming. ### Fenwick Trees (BIT - Binary Indexed Trees) - **Definition:** A data structure that can efficiently update elements and calculate prefix sums in a table of numbers. More space-efficient than segment trees for prefix sums. - **Operations:** - **`update(index, value)`:** Adds `value` to element at `index`. Updates ancestors. $O(\log n)$. - **`query(index)`:** Calculates prefix sum up to `index`. Sums values from ancestors. $O(\log n)$. - **`rangeQuery(L, R)`:** `query(R) - query(L-1)`. $O(\log n)$. - **Mechanism:** Uses bit manipulation (`x & (-x)`) to find parent/next index based on lowest set bit. - **Applications:** Prefix sums, frequency counts, competitive programming. ### Disjoint Set Union (DSU) / Union-Find - **Definition:** Data structure that keeps track of a set of elements partitioned into a number of disjoint (non-overlapping) subsets. - **Operations:** - **`makeSet(x)`:** Creates a new set containing only `x`. - **`find(x)`:** Returns a representative of the set containing `x`. Used to check if two elements are in the same set. - **`union(x, y)`:** Merges the sets containing `x` and `y` into a single set. - **Optimizations:** - **Path Compression:** During `find(x)`, make every node on the path from `x` to the root point directly to the root. - **Union by Rank/Size:** When merging two sets, attach the root of the smaller tree to the root of the larger tree (based on rank/height or size). - **Time Complexity:** Nearly constant amortized time, $O(\alpha(n))$, where $\alpha$ is the inverse Ackermann function, which grows extremely slowly. - **Applications:** Kruskal's algorithm for MST, connected components in a graph, network connectivity. ### Suffix Structures #### Suffix Arrays - **Definition:** A sorted array of all suffixes of a string. - **Construction:** $O(N \log N)$ or $O(N)$ using advanced algorithms (e.g., DC3, SA-IS). - **Applications:** Pattern matching, finding longest common substring, genome analysis. #### Suffix Trees - **Definition:** A compressed trie of all suffixes of a given string. - **Construction:** $O(N)$ using Ukkonen's algorithm. - **Applications:** Much faster for many string problems, but more complex to implement than suffix arrays. ### Skip Lists - **Definition:** A probabilistic data structure that allows $O(\log n)$ average time complexity for search, insertion, and deletion operations. It consists of multiple layers of sorted linked lists. - **Structure:** - Layer 0 is a standard sorted linked list. - Each subsequent layer acts as an "express lane" for the layer below it, containing a subset of its elements. - Elements are promoted to higher levels probabilistically. - **Operations:** - **`search`:** Start at the highest level, move right until `key` is exceeded or current node is greater than `key`. Drop down a level and repeat. - **`insert`:** Insert at level 0, then probabilistically decide whether to promote it to higher levels. - **Advantages:** Simpler to implement than balanced BSTs, good average-case performance. - **Applications:** Concurrent dictionaries, distributed systems.