Data Structures & Algorithms
Cheatsheet Content
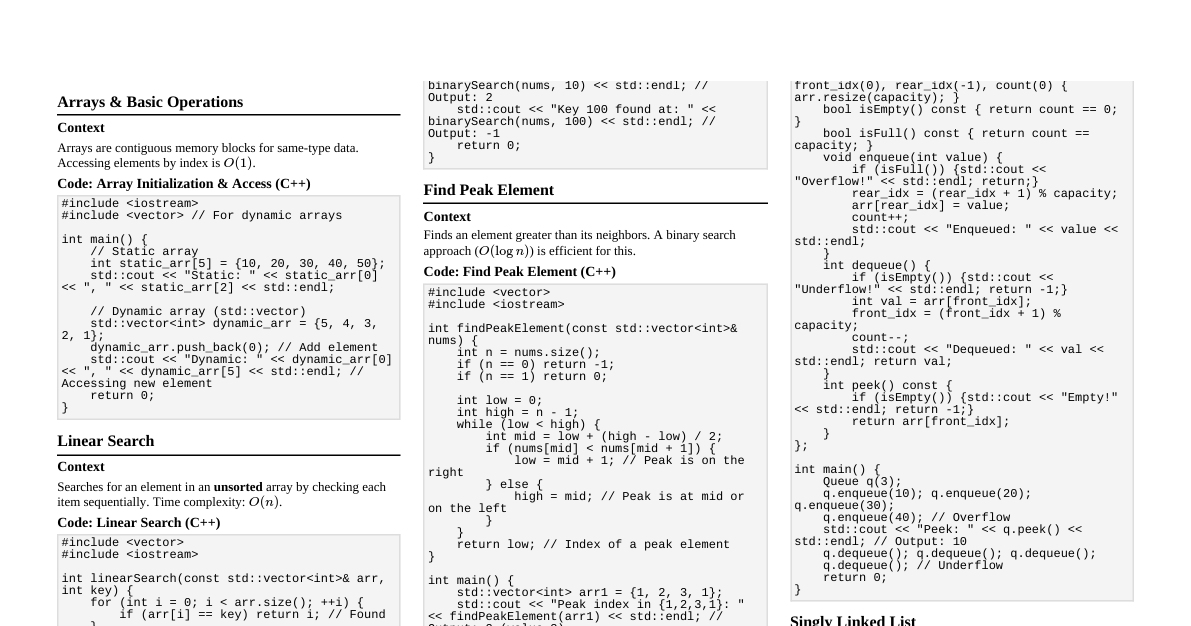
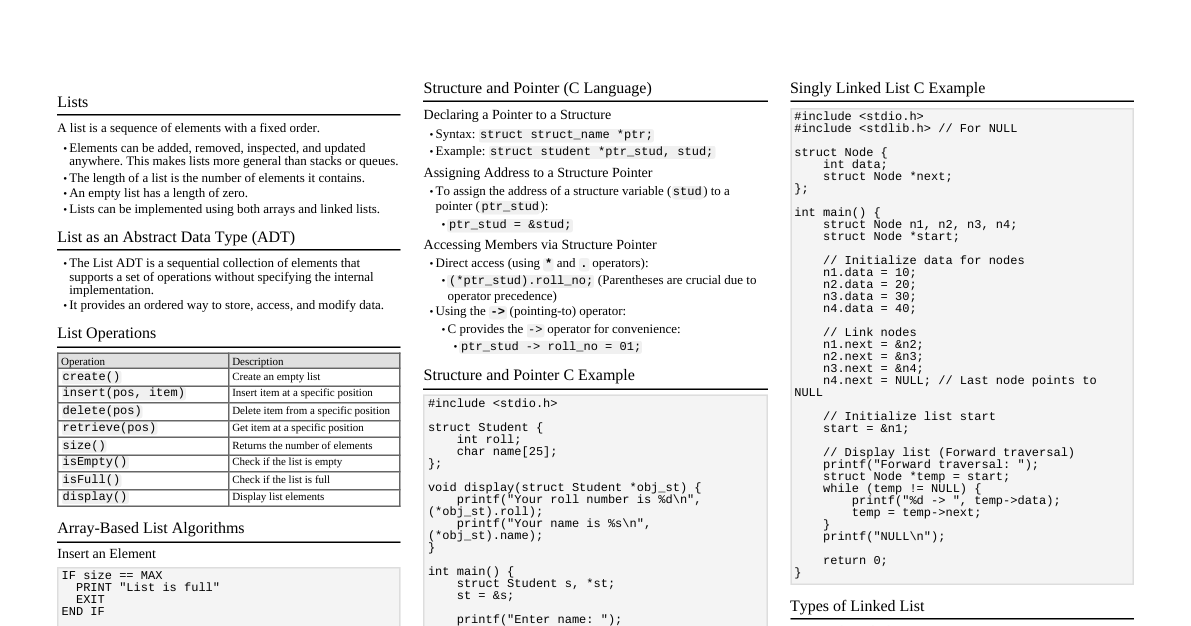
### Time & Space Complexity - **Big O Notation:** Describes the upper bound of an algorithm's growth rate. - $O(1)$: Constant time (e.g., array access, hash map insert/lookup) - $O(\log n)$: Logarithmic time (e.g., binary search) - $O(n)$: Linear time (e.g., array traversal, linear search) - $O(n \log n)$: Log-linear time (e.g., merge sort, heap sort) - $O(n^2)$: Quadratic time (e.g., bubble sort, insertion sort, selection sort) - $O(2^n)$: Exponential time (e.g., recursive Fibonacci) - $O(n!)$: Factorial time (e.g., traveling salesman brute force) - **Space Complexity:** Amount of memory an algorithm uses. - $O(1)$: Constant (e.g., in-place sorting) - $O(\log n)$: Logarithmic (e.g., recursive call stack for binary search) - $O(n)$: Linear (e.g., arrays, linked lists, hash tables) ### Arrays - **Definition:** Collection of elements identified by index. Fixed size in many languages. - **Operations:** - Access: $O(1)$ - Search (unordered): $O(n)$ - Insert/Delete (at end): $O(1)$ amortized - Insert/Delete (at middle/beginning): $O(n)$ - **Use Cases:** Storing collections, fixed-size data, building blocks for other structures. - **Variants:** Dynamic Arrays (e.g., `ArrayList` in Java, `list` in Python) resize automatically, amortized $O(1)$ for append. ### Linked Lists - **Definition:** Sequence of nodes, each containing data and a reference (link) to the next node. - **Types:** - **Singly:** Node points to next node. - **Doubly:** Node points to next and previous node. - **Circular:** Last node points back to the first. - **Operations:** - Access: $O(n)$ - Search: $O(n)$ - Insert/Delete (at beginning): $O(1)$ - Insert/Delete (at middle/end, if previous node known): $O(1)$ - **Use Cases:** Dynamic data, implementing stacks/queues, managing memory. ### Stacks - **Definition:** LIFO (Last In, First Out) data structure. - **Operations:** - `push(item)`: Add item to top. $O(1)$ - `pop()`: Remove and return item from top. $O(1)$ - `peek()`: Return top item without removing. $O(1)$ - `isEmpty()`: Check if stack is empty. $O(1)$ - **Implementation:** Array or Linked List. - **Use Cases:** Function call stack, undo/redo, expression evaluation, backtracking. ### Queues - **Definition:** FIFO (First In, First Out) data structure. - **Operations:** - `enqueue(item)`: Add item to rear. $O(1)$ - `dequeue()`: Remove and return item from front. $O(1)$ - `front()`: Return front item without removing. $O(1)$ - `isEmpty()`: Check if queue is empty. $O(1)$ - **Implementation:** Array (circular array for efficiency) or Linked List. - **Use Cases:** BFS (Breadth-First Search), task scheduling, print queues. ### Trees - **Definition:** Hierarchical data structure with a root node and subtrees of children nodes. - **Terminology:** Root, Node, Parent, Child, Sibling, Leaf, Edge, Path, Depth, Height. - **Types:** - **Binary Tree:** Each node has at most two children. - **Binary Search Tree (BST):** Left child Node -> Right (sorted output for BST). - **Pre-order (NLR):** Node -> Left -> Right (copying tree, expression tree prefix). - **Post-order (LRN):** Left -> Right -> Node (deleting tree, expression tree postfix). - **Level-order (BFS):** Level by level using a queue. ### Graphs - **Definition:** Set of vertices (nodes) and edges connecting them. - **Terminology:** Vertex, Edge, Directed/Undirected, Weighted/Unweighted, Path, Cycle, Degree. - **Representation:** - **Adjacency Matrix:** `adj[i][j] = 1` if edge from `i` to `j`, else `0`. - Space: $O(V^2)$ - Add/Remove Edge: $O(1)$ - Check Adjacency: $O(1)$ - Iterate Neighbors: $O(V)$ - **Adjacency List:** Array of lists, where `adj[i]` contains neighbors of `i`. - Space: $O(V + E)$ - Add/Remove Edge: $O(1)$ (for list, $O(degree)$ for set) - Check Adjacency: $O(degree)$ - Iterate Neighbors: $O(degree)$ - **Traversal Algorithms:** - **Breadth-First Search (BFS):** Uses a queue, finds shortest path in unweighted graph. $O(V + E)$ - **Depth-First Search (DFS):** Uses a stack or recursion, explores as far as possible along each branch. $O(V + E)$ - **Common Algorithms:** - **Dijkstra's Algorithm:** Shortest path from single source in weighted, non-negative edge graph. $O(E \log V)$ with priority queue. - **Bellman-Ford Algorithm:** Shortest path from single source in weighted graph with negative edges (detects negative cycles). $O(VE)$ - **Floyd-Warshall Algorithm:** All-pairs shortest path. $O(V^3)$ - **Prim's Algorithm:** Minimum Spanning Tree (MST) for dense graphs ($O(V^2)$). - **Kruskal's Algorithm:** MST for sparse graphs ($O(E \log E)$ or $O(E \log V)$ with disjoint set). - **Topological Sort:** Linear ordering of vertices in a DAG (Directed Acyclic Graph). $O(V + E)$ ### Hash Tables (Hash Maps) - **Definition:** Stores key-value pairs using a hash function to map keys to array indices. - **Operations:** - Insert, Delete, Search: $O(1)$ average, $O(n)$ worst case (all keys hash to same slot). - **Collision Resolution:** - **Separate Chaining:** Each array slot stores a linked list of key-value pairs that hash to that slot. - **Open Addressing:** If a slot is occupied, probe for the next available slot (linear probing, quadratic probing, double hashing). - **Load Factor:** `(Number of entries) / (Table size)`. When too high, resize (rehash) the table. - **Use Cases:** Caching, symbol tables, database indexing, unique element checking. ### Sorting Algorithms - **Comparison Sorts (Lower Bound $\Omega(n \log n)$):** - **Merge Sort:** Divide and conquer. Stable. $O(n \log n)$ time, $O(n)$ space. - **Heap Sort:** Uses a max-heap. In-place. $O(n \log n)$ time, $O(1)$ space. - **Quick Sort:** Divide and conquer. Pivot selection critical. $O(n \log n)$ average, $O(n^2)$ worst case. $O(\log n)$ space average. Unstable. - **Insertion Sort:** Builds final sorted array one item at a time. Efficient for small or nearly sorted lists. $O(n^2)$ time, $O(1)$ space. Stable. - **Selection Sort:** Finds minimum, swaps with current position. $O(n^2)$ time, $O(1)$ space. Unstable. - **Bubble Sort:** Repeatedly steps through list, compares adjacent elements and swaps. $O(n^2)$ time, $O(1)$ space. Stable. - **Non-Comparison Sorts:** - **Counting Sort:** For integers within a specific range. $O(n+k)$ time, $O(n+k)$ space (k is range size). Stable. - **Radix Sort:** Sorts integers by processing digits from least to most significant (or vice-versa). $O(d(n+k))$ time (d is number of digits). Stable. ### Dynamic Programming - **Definition:** Method for solving complex problems by breaking them down into simpler subproblems. Store results of subproblems to avoid recomputation. - **Key Characteristics:** - **Overlapping Subproblems:** Same subproblems are encountered multiple times. - **Optimal Substructure:** Optimal solution to problem can be constructed from optimal solutions to its subproblems. - **Approaches:** - **Memoization (Top-Down):** Recursive solution with caching. - **Tabulation (Bottom-Up):** Iterative solution building up from base cases. - **Examples:** Fibonacci sequence, knapsack problem, longest common subsequence, edit distance. ### Greedy Algorithms - **Definition:** Makes the locally optimal choice at each stage with the hope of finding a global optimum. - **Characteristics:** Doesn't always guarantee optimal solution. - **Examples:** Dijkstra's Algorithm (for non-negative weights), Kruskal's/Prim's for MST, activity selection problem, change-making problem. ### Backtracking - **Definition:** Recursive algorithm for finding all (or some) solutions to computational problems, notably constraint satisfaction problems. It incrementally builds candidates to the solutions, and abandons a candidate ("backtracks") as soon as it determines that the candidate cannot possibly be completed to a valid solution. - **Structure:** ``` function solve(current_state): if current_state is a solution: add to results return for each choice in possible_choices(current_state): if choice is valid: apply choice to current_state solve(new_state) undo choice (backtrack) ``` - **Use Cases:** N-Queens, Sudoku solver, permutation generation, subset sum. ### Divide and Conquer - **Definition:** Breaks a problem into smaller subproblems of the same type, solves them recursively, and combines their solutions. - **Steps:** 1. **Divide:** Break the problem into subproblems. 2. **Conquer:** Solve the subproblems recursively. If subproblems are small enough, solve them directly. 3. **Combine:** Combine the solutions of the subproblems to get the solution for the original problem. - **Examples:** Merge Sort, Quick Sort, Binary Search, Strassen's Matrix Multiplication.