Statistical Inference
Shared 5/6/2026•0 views
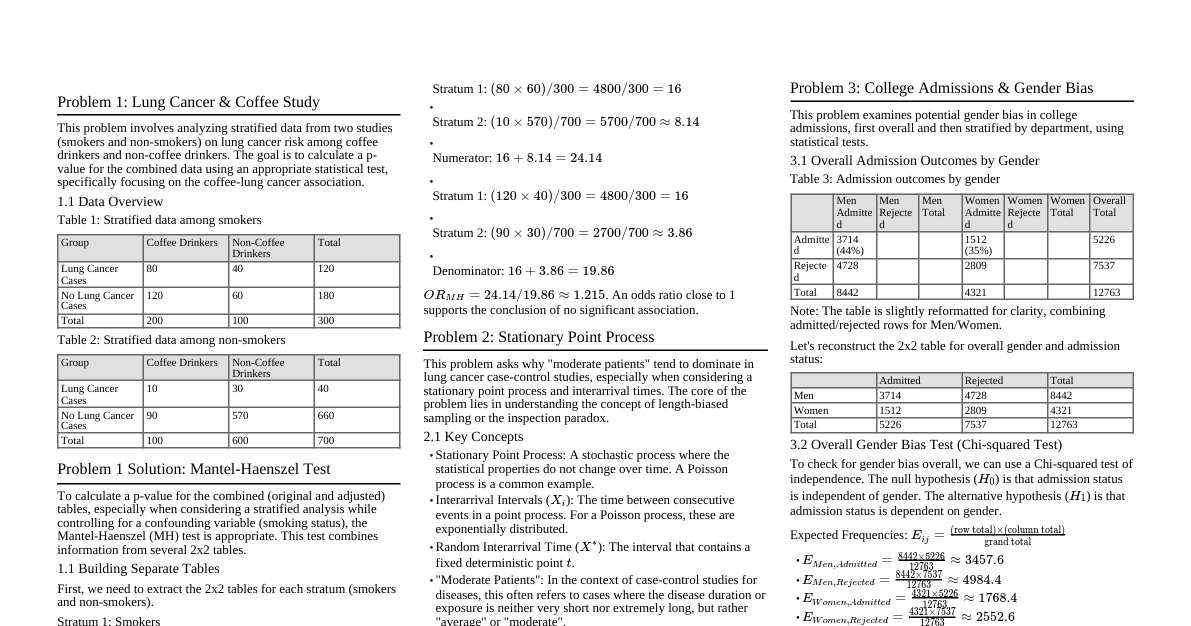
### Commonly Used Probability Distributions Understanding these distributions is fundamental for statistical inference, as they model various types of data and form the basis for many tests and estimations. #### Continuous Distributions (PDFs) - **Normal Distribution** $X \sim \mathcal{N}(\mu, \sigma^2)$ - **PDF:** $f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}$ - **Parameters:** $\mu$ (mean), $\sigma^2$ (variance). - **Use Case:** Models many natural phenomena; crucial for the Central Limit Theorem. - **Special Case:** Standard Normal ($Z \sim \mathcal{N}(0,1)$) when $\mu=0, \sigma^2=1$. - **Exponential Distribution** $X \sim \text{Exponential}(\lambda)$ - **PDF:** $f(x) = \begin{cases} \lambda e^{-\lambda x} & \text{for } x \ge 0 \\ 0 & \text{for } x < 0 \end{cases}$ - **Parameter:** $\lambda$ (rate parameter, $\lambda > 0$). Mean is $1/\lambda$, variance is $1/\lambda^2$. - **Use Case:** Models the time until an event occurs in a Poisson process (events occurring continuously and independently at a constant average rate). - **Beta Distribution** $X \sim \text{Beta}(\alpha, \beta)$ - **PDF:** $f(x) = \begin{cases} \frac{1}{B(\alpha, \beta)} x^{\alpha-1}(1-x)^{\beta-1} & \text{for } 0 < x < 1 \\ 0 & \text{otherwise} \end{cases}$ - **Parameters:** $\alpha, \beta$ (shape parameters, $>0$). $B(\alpha, \beta)$ is the Beta function. - **Use Case:** Models probabilities or proportions, often used as a prior distribution in Bayesian inference for binomial proportions (conjugate prior). - **Gamma Distribution** $X \sim \text{Gamma}(\alpha, \beta)$ - **PDF:** $f(x) = \begin{cases} \frac{\beta^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\beta x} & \text{for } x > 0 \\ 0 & \text{for } x \le 0 \end{cases}$ - **Parameters:** $\alpha$ (shape), $\beta$ (rate, $>0$). $\Gamma(\alpha)$ is the Gamma function. Mean is $\alpha/\beta$, variance is $\alpha/\beta^2$. - **Use Case:** Models waiting times; sums of exponential random variables. It is a conjugate prior for the rate parameter of Poisson and Exponential distributions. - **Uniform Distribution** $X \sim \text{Uniform}(a, b)$ - **PDF:** $f(x) = \begin{cases} \frac{1}{b-a} & \text{for } a \le x \le b \\ 0 & \text{otherwise} \end{cases}$ - **Parameters:** $a$ (minimum), $b$ (maximum). - **Use Case:** Models situations where all outcomes in an interval are equally likely. #### Discrete Distributions (PMFs) - **Bernoulli Distribution** $X \sim \text{Bernoulli}(p)$ - **PMF:** $P(x) = p^x (1-p)^{1-x} \quad \text{for } x \in \{0, 1\}$ - **Parameter:** $p$ (probability of success). - **Use Case:** Models a single trial with two possible outcomes (success/failure). - **Binomial Distribution** $X \sim \text{Binomial}(n, p)$ - **PMF:** $P(x) = \begin{cases} \binom{n}{x} p^x (1-p)^{n-x} & \text{for } x = 0, 1, \dots, n \\ 0 & \text{otherwise} \end{cases}$ - **Parameters:** $n$ (number of trials), $p$ (probability of success on each trial). - **Use Case:** Models the number of successes in a fixed number of independent Bernoulli trials. - **Poisson Distribution** $X \sim \text{Poisson}(\lambda)$ - **PMF:** $P(x) = \begin{cases} \frac{e^{-\lambda} \lambda^x}{x!} & \text{for } x = 0, 1, 2, \dots \\ 0 & \text{otherwise} \end{cases}$ - **Parameter:** $\lambda$ (average rate of events in an interval). - **Use Case:** Models the number of events occurring in a fixed interval of time or space, given a constant average rate. - **Geometric Distribution** $X \sim \text{Geometric}(p)$ - **PMF:** $P(x) = \begin{cases} (1-p)^{x-1} p & \text{for } x = 1, 2, \dots \\ 0 & \text{otherwise} \end{cases}$ - **Parameter:** $p$ (probability of success). - **Use Case:** Models the number of Bernoulli trials needed to get the first success. ### Bayesian Statistics Bayesian statistics views parameters as random variables, allowing for the incorporation of prior knowledge through probability distributions. This contrasts with classical (frequentist) statistics, where parameters are fixed, unknown constants. #### Core Concepts - **Prior Distribution ($f_\Theta(\theta)$):** Represents initial beliefs about the parameter $\theta$ before observing any data. It quantifies the uncertainty about $\theta$. - **Likelihood Function ($f_{X|\Theta}(x|\theta)$):** Describes the probability of observing the data $x$ given a specific value of the parameter $\theta$. It's the same as in classical statistics. - **Posterior Distribution ($f_{\Theta|X}(\theta|x)$):** The updated belief about the parameter $\theta$ after observing the data $x$. It combines the prior belief with the information from the data. - **Bayes' Theorem:** The fundamental rule for updating beliefs: $$f_{\Theta|X}(\theta|x) = \frac{f_{X|\Theta}(x|\theta) f_\Theta(\theta)}{f_X(x)}$$ where $f_X(x) = \int f_{X|\Theta}(x|\theta) f_\Theta(\theta) d\theta$ is the marginal likelihood (evidence), a normalizing constant. Often written as: $$\text{Posterior} \propto \text{Likelihood} \times \text{Prior}$$ #### Steps in Bayesian Inference 1. **Specify Prior:** Choose a prior distribution $f_\Theta(\theta)$ for the unknown parameter(s). This can be informative (based on previous studies/expert opinion) or non-informative (to let the data speak for itself). 2. **Formulate Likelihood:** Define the likelihood function $f_{X|\Theta}(x|\theta)$ based on the data-generating process. 3. **Calculate Posterior:** Use Bayes' theorem to compute the posterior distribution $f_{\Theta|X}(\theta|x)$. This step often involves complex integration, especially for non-conjugate priors or high-dimensional parameters, and may require numerical methods like Markov Chain Monte Carlo (MCMC). 4. **Make Inferences:** Use the posterior distribution to draw conclusions about $\theta$. This can involve: - **Point Estimation:** Finding a single "best" estimate for $\theta$ (e.g., posterior mean, median, or mode). - **Interval Estimation:** Constructing credible intervals for $\theta$. - **Hypothesis Testing:** Comparing competing hypotheses about $\theta$. - **Prediction:** Predicting future observations. #### Advantages of Bayesian Approach - Directly provides probability distributions for parameters, reflecting uncertainty. - Naturally incorporates prior knowledge. - Coherent framework for updating beliefs as new data arrives. - Can handle complex models and small sample sizes. #### Disadvantages of Bayesian Approach - Choice of prior can be subjective and influence results. - Computational intensity for complex models. #### Typical Procedure for Bayesian Problems 1. **Identify Parameter(s) of Interest ($\theta$):** What are you trying to estimate or make inferences about? 2. **Select a Prior Distribution ($f_\Theta(\theta)$):** Based on existing knowledge, domain expertise, or by choosing a non-informative prior if little is known. 3. **Define the Likelihood Function ($f_{X|\Theta}(x|\theta)$):** This describes how your data $x$ is generated given $\theta$. 4. **Collect Data ($x$):** Obtain your observed sample. 5. **Compute the Posterior Distribution ($f_{\Theta|X}(\theta|x)$):** Multiply the likelihood by the prior and normalize. If a conjugate prior is used, this step is often analytical. Otherwise, numerical methods might be needed. 6. **Summarize the Posterior:** Calculate point estimates (MAP, posterior mean/median), credible intervals, or visualize the distribution to answer your question. ### Conjugate Priors A **conjugate prior** is a prior distribution for which the resulting posterior distribution belongs to the same parametric family as the prior distribution. #### Benefits of Conjugacy - **Computational Simplicity:** Makes the calculation of the posterior distribution analytically tractable, avoiding complex numerical integration. - **Interpretability:** The posterior has the same mathematical form as the prior, making it easier to understand how the data updated the prior beliefs. - **Sequential Updating:** If new data arrives, the current posterior can serve as the prior for the next update, maintaining the same distributional form. #### Common Conjugate Pairs (Likelihood-Prior-Posterior) | Likelihood Function (Data $X$) | Parameter ($\theta$) | Conjugate Prior Distribution (for $\theta$) | Posterior Distribution (for $\theta$ given $X$) | | :--------------------------------------------- | :------------------- | :------------------------------------------ | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | **Bernoulli($p$)** or **Binomial($n, p$)** | Probability $p$ | Beta($\alpha, \beta$) | Beta($\alpha + \text{sum of successes}, \beta + \text{sum of failures}$) (i.e., Beta($\alpha + \sum x_i, \beta + n - \sum x_i$) for Binomial with $n$ trials and $\sum x_i$ successes, or $n$ Bernoulli trials with $\sum x_i$ successes) | | **Poisson($\lambda$)** | Rate $\lambda$ | Gamma($\alpha, \beta$) | Gamma($\alpha + \sum x_i, \beta + \text{number of observations}$ ) (i.e., Gamma($\alpha + \sum x_i, \beta + n$)) | | **Normal($\mu, \sigma^2$)** (known $\sigma^2$) | Mean $\mu$ | Normal($\mu_0, \tau_0^2$) | Normal($\frac{\tau_0^2 \sum x_i + \sigma^2 \mu_0}{n\tau_0^2 + \sigma^2}, \frac{\sigma^2 \tau_0^2}{n\tau_0^2 + \sigma^2}$) | | **Normal($\mu, \sigma^2$)** (known $\mu$) | Variance $\sigma^2$ | Inverse-Gamma($\alpha, \beta$) | Inverse-Gamma($\alpha + n/2, \beta + \frac{1}{2} \sum (x_i - \mu)^2$) | | **Multinomial($p_1, \dots, p_K$)** | Probabilities $p_k$ | Dirichlet($\alpha_1, \dots, \alpha_K$) | Dirichlet($\alpha_1 + n_1, \dots, \alpha_K + n_K$) where $n_k$ is the count of observations for category $k$. | | **Exponential($\lambda$)** | Rate $\lambda$ | Gamma($\alpha, \beta$) | Gamma($\alpha + n, \beta + \sum x_i$) | #### Example: Bernoulli Likelihood with Beta Prior - **Scenario:** We observe $X_1, \dots, X_n$ i.i.d. Bernoulli trials, where $X_i=1$ for success and $X_i=0$ for failure. We want to infer the underlying probability of success, $p$. - **Likelihood:** For a single observation $X_i$, $P(X_i=x_i|p) = p^{x_i}(1-p)^{1-x_i}$. For the entire dataset $x = (x_1, \dots, x_n)$, the likelihood is $L(p|x) = \prod_{i=1}^n p^{x_i}(1-p)^{1-x_i} = p^{\sum x_i} (1-p)^{n-\sum x_i}$. Let $S = \sum x_i$ be the number of successes. - **Prior:** We choose a Beta($\alpha, \beta$) distribution for $p$, because it's defined on $[0,1]$ and is conjugate to the Bernoulli likelihood. The PDF is $f(p) = \frac{1}{B(\alpha, \beta)} p^{\alpha-1} (1-p)^{\beta-1}$. - **Posterior Calculation:** $$f(p|x) \propto L(p|x) f(p) \propto p^S (1-p)^{n-S} \cdot p^{\alpha-1} (1-p)^{\beta-1}$$ $$f(p|x) \propto p^{\alpha + S - 1} (1-p)^{\beta + n - S - 1}$$ This is the kernel of a Beta distribution with new parameters $\alpha' = \alpha + S$ and $\beta' = \beta + n - S$. - **Conclusion:** The posterior distribution for $p$ is Beta($\alpha + S, \beta + n - S$). The prior parameters $\alpha$ and $\beta$ can be thought of as prior "pseudo-counts" of successes and failures. The posterior simply adds the observed successes and failures to these pseudo-counts. ### Prediction, Estimation, and Hypothesis Testing These are the three main objectives of statistical inference. #### Prediction - **Goal:** To forecast the value(s) of future observations ($X^*$) based on observed data ($x$) and statistical models. - **Bayesian Prediction:** Involves computing the **posterior predictive distribution**, which averages the likelihood of new data over the posterior distribution of the parameters. $$f_{X^*|X}(x^*|x) = \int f_{X^*|\Theta}(x^*|\theta) f_{\Theta|X}(\theta|x) d\theta$$ This accounts for uncertainty in the parameter $\theta$. - **Classical Prediction:** Typically involves using point estimates for parameters (e.g., MLE) and plugging them into the likelihood function to predict future observations. This approach often underestimates uncertainty as it doesn't account for estimation error in $\hat{\theta}$. $$f_{X^*|X}(x^*|x) \approx f_{X^*}(x^*; \hat{\theta})$$ - **Prediction Intervals:** Intervals for future observations, wider than confidence/credible intervals for parameters because they account for both parameter uncertainty and inherent variability in the data. #### Estimation - **Goal:** To infer the value of an unknown population parameter ($\theta$) from sample data ($x$). - **Point Estimation:** Provides a single "best guess" for the parameter. - **Classical:** - **Maximum Likelihood Estimator (MLE):** $\hat{\theta}_{MLE} = \arg \max_{\theta} L(\theta|x)$. The value of $\theta$ that makes the observed data most probable. - **Method of Moments Estimator (MME):** Equates sample moments to population moments and solves for $\theta$. - **Bayesian:** - **Maximum A Posteriori (MAP) Estimator:** $\hat{\theta}_{MAP} = \arg \max_{\theta} f_{\Theta|X}(\theta|x)$. The mode of the posterior distribution. - **`argmax` explanation:** The `argmax` function returns the argument (input value) that produces the maximum value of a given expression. So, $\arg \max_{\theta} f_{\Theta|X}(\theta|x)$ means "the value of $\theta$ that maximizes the posterior probability density function $f_{\Theta|X}(\theta|x)$". - **Posterior Mean/Median:** Often used as point estimates, especially when the posterior is symmetric or skewed, respectively. - **Interval Estimation:** Provides a range of plausible values for the parameter. - **Classical: Confidence Interval (CI):** A range $[\hat{\theta}_L, \hat{\theta}_U]$ such that, if the experiment were repeated many times, a $(1-\alpha)\%$ proportion of these intervals would contain the true parameter $\theta$. The parameter $\theta$ is fixed, the interval is random. - **Bayesian: Credible Interval (CrI):** A range $[\theta_L, \theta_U]$ such that the posterior probability of $\theta$ falling within this range is $(1-\alpha)\%$. The parameter $\theta$ is a random variable, and the interval is fixed after data is observed. #### Hypothesis Testing - **Goal:** To assess the evidence against a null hypothesis ($H_0$) in favor of an alternative hypothesis ($H_1$). - **Classical (Frequentist) Hypothesis Testing:** - **Define Hypotheses:** $H_0$ (status quo) and $H_1$ (what we want to test). - **Choose Significance Level ($\alpha$):** The maximum tolerable Type I error rate (false positive). - **Select Test Statistic:** A function of the sample data used to make a decision. - **Determine Rejection Region (or calculate p-value):** The set of values of the test statistic for which $H_0$ is rejected. - **Make Decision:** If the observed test statistic falls in the rejection region (or p-value $\le \alpha$), reject $H_0$. Otherwise, fail to reject $H_0$. - **Bayesian Hypothesis Testing:** - **Compare Posterior Probabilities:** Directly compare the posterior probabilities of the hypotheses, $P(H_0|x)$ and $P(H_1|x)$. - **Bayes Factor:** A ratio of marginal likelihoods, $BF_{10} = \frac{P(x|H_1)}{P(x|H_0)}$, which quantifies the evidence provided by the data in favor of $H_1$ over $H_0$. - Posterior odds: $\frac{P(H_1|x)}{P(H_0|x)} = BF_{10} \times \frac{P(H_1)}{P(H_0)}$. - Decision based on posterior odds or Bayes factor. ### Sample Statistics Sample statistics are functions of observed data used to estimate unknown population parameters. They summarize characteristics of the sample. #### Random Sample - A **random sample** $X_1, X_2, \dots, X_n$ is a set of $n$ independent and identically distributed (i.i.d.) random variables drawn from the same population distribution. #### Key Sample Statistics - **Sample Mean ($\bar{X}$):** - Definition: $\bar{X} = \frac{1}{n} \sum_{i=1}^n X_i$ - **Properties:** - **Unbiased Estimator** of the population mean $\mu$: $E[\bar{X}] = \mu$. - **Consistency:** As $n \to \infty$, $\bar{X} \to \mu$ (by Law of Large Numbers). - **Variance:** $\text{Var}(\bar{X}) = \frac{\sigma^2}{n}$. - **Central Limit Theorem (CLT)** - **Statement:** If $X_1, X_2, \dots, X_n$ is a random sample of size $n$ taken from a population with mean $\mu$ and finite variance $\sigma^2$, then the sampling distribution of the sample mean $\bar{X}$ approaches a normal distribution with mean $\mu$ and variance $\sigma^2/n$ as $n \to \infty$. - **Formally:** $$ \sqrt{n}(\bar{X} - \mu) \xrightarrow{d} \mathcal{N}(0, \sigma^2) $$ or equivalently, for large $n$: $$ \bar{X} \approx \mathcal{N}\left(\mu, \frac{\sigma^2}{n}\right) $$ And the standardized sample mean $Z$ is approximately standard normal: $$ Z = \frac{\bar{X} - \mu}{\sigma/\sqrt{n}} \approx \mathcal{N}(0,1) $$ - **Importance:** The CLT is foundational for classical statistical inference. It allows us to use normal distribution theory to construct confidence intervals and perform hypothesis tests on population means, even if the original population distribution is not normal, provided the sample size is sufficiently large (typically $n \ge 30$). - **Sample Variance ($S^2$):** - **Biased Sample Variance:** $S_{biased}^2 = \frac{1}{n} \sum_{i=1}^n (X_i - \bar{X})^2$ - $E[S_{biased}^2] = \frac{n-1}{n} \sigma^2 \neq \sigma^2$ - **Unbiased Sample Variance:** $S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \bar{X})^2$ - **Unbiased Estimator** of the population variance $\sigma^2$: $E[S^2] = \sigma^2$. - The denominator $n-1$ is known as **degrees of freedom**. It arises because $\bar{X}$ is used to estimate $\mu$, which "uses up" one degree of freedom. - **Sample Standard Deviation ($S$):** $S = \sqrt{S^2}$. Note that $S$ is generally a biased estimator for $\sigma$. - **Sample Proportion ($\hat{p}$):** - Used for Bernoulli or Binomial data. If $X_i \in \{0, 1\}$, then $\hat{p} = \bar{X} = \frac{1}{n} \sum_{i=1}^n X_i$. - **Unbiased Estimator** of the population proportion $p$: $E[\hat{p}] = p$. - **Variance:** $\text{Var}(\hat{p}) = \frac{p(1-p)}{n}$. - For large $n$, $\hat{p}$ is approximately normally distributed: $\hat{p} \approx \mathcal{N}(p, \frac{p(1-p)}{n})$. #### Order Statistics - When a sample $X_1, \dots, X_n$ is arranged in ascending order, the resulting values $X_{(1)} \le X_{(2)} \le \dots \le X_{(n)}$ are called **order statistics**. - **Sample Minimum:** $X_{(1)} = \min(X_1, \dots, X_n)$ - **Sample Maximum:** $X_{(n)} = \max(X_1, \dots, X_n)$ - **Sample Median:** For odd $n$, $X_{((n+1)/2)}$. For even $n$, any value between $X_{(n/2)}$ and $X_{(n/2+1)}$ (often average is used). Resists outliers better than the mean. - **Sample Range:** $X_{(n)} - X_{(1)}$. #### Sufficiency - A statistic $T(X_1, \dots, X_n)$ is **sufficient** for a parameter $\theta$ if it contains all the information about $\theta$ present in the sample. That is, the conditional distribution of the data given $T(X_1, \dots, X_n)$ does not depend on $\theta$. - **Fisher-Neyman Factorization Theorem:** $T(X)$ is sufficient for $\theta$ if and only if the likelihood function can be factored as $L(\theta|x) = g(T(x), \theta) h(x)$, where $h(x)$ does not depend on $\theta$. #### Typical Procedure for Sample Statistics Problems 1. **Identify the Population Parameter of Interest:** Is it the mean ($\mu$), variance ($\sigma^2$), or proportion ($p$)? 2. **Determine Sample Characteristics:** What is the sample size ($n$), sample mean ($\bar{x}$), sample variance ($s^2$), or sample proportion ($\hat{p}$)? 3. **Check Assumptions:** Does the population follow a specific distribution (e.g., Normal)? Is the sample size large enough for CLT to apply? 4. **Calculate the Appropriate Sample Statistic:** Use the formulas for $\bar{X}$, $S^2$, or $\hat{p}$. 5. **Interpret the Statistic:** Understand what the calculated sample statistic tells you about the corresponding population parameter, keeping in mind its properties (e.g., unbiasedness, variance). ### Classical Point Estimation (Detailed) Point estimation aims to provide a single value that best approximates an unknown population parameter. #### Properties of Estimators - **Unbiasedness:** An estimator $\hat{\Theta}$ is unbiased for $\theta$ if $E[\hat{\Theta}] = \theta$. This means, on average, the estimator hits the true parameter value. - Bias: $B(\hat{\Theta}) = E[\hat{\Theta}] - \theta$. - **Consistency:** An estimator $\hat{\Theta}_n$ (based on sample size $n$) is consistent for $\theta$ if it converges in probability to $\theta$ as $n \to \infty$. That is, for any $\epsilon > 0$, $P(|\hat{\Theta}_n - \theta| ### Confidence Intervals A **confidence interval (CI)** is a range of values that is likely to contain an unknown population parameter with a certain level of confidence. It quantifies the uncertainty associated with a point estimate. #### Interpretation - A $(1-\alpha)100\%$ confidence interval for a parameter $\theta$ means that if we were to repeat the sampling process many times, $(1-\alpha)100\%$ of the constructed intervals would contain the true value of $\theta$. - **Crucially:** The true parameter $\theta$ is considered a fixed, unknown constant. The interval (its endpoints) is random because it depends on the sample data. #### General Form - A confidence interval is typically expressed as: $\text{Point Estimate} \pm \text{Margin of Error}$. - Margin of Error = (Critical Value) $\times$ (Standard Error of the Estimate). #### Confidence Interval for Population Mean ($\mu$) ##### Case 1: Population Variance $\sigma^2$ is KNOWN - **Assumptions:** - Sample $X_1, \dots, X_n$ is i.i.d. - Population variance $\sigma^2$ is known. - Either the population is normally distributed, OR the sample size $n$ is large ($n \ge 30$) so that the Central Limit Theorem applies. - **Test Statistic:** $Z = \frac{\bar{X} - \mu}{\sigma/\sqrt{n}} \sim \mathcal{N}(0,1)$. - **$(1-\alpha)100\%$ CI:** $$ \bar{x} \pm z_{\alpha/2} \frac{\sigma}{\sqrt{n}} $$ where $z_{\alpha/2}$ is the critical value from the standard normal distribution such that $P(Z > z_{\alpha/2}) = \alpha/2$. ##### Case 2: Population Variance $\sigma^2$ is UNKNOWN - **Subcase 2a: Large Sample Size ($n \ge 30$)** - **Assumptions:** - Sample $X_1, \dots, X_n$ is i.i.d. - Population variance $\sigma^2$ is unknown. - Sample size $n$ is large ($n \ge 30$). - We use the sample standard deviation $s = \sqrt{\frac{1}{n-1}\sum(X_i-\bar{X})^2}$ as an estimate for $\sigma$. Due to large $n$ (and CLT), we can still approximate the sampling distribution of $\bar{X}$ as normal. - **Test Statistic:** $Z \approx \frac{\bar{X} - \mu}{s/\sqrt{n}} \sim \mathcal{N}(0,1)$ (approximately). - **$(1-\alpha)100\%$ CI:** $$ \bar{x} \pm z_{\alpha/2} \frac{s}{\sqrt{n}} $$ - **Subcase 2b: Small Sample Size ($n t_{\alpha/2, n-1}) = \alpha/2$. #### Confidence Interval for Population Proportion ($p$) - **Assumptions:** - Large sample size, typically $n\hat{p} \ge 5$ and $n(1-\hat{p}) \ge 5$ (or $n\hat{p} \ge 10$ and $n(1-\hat{p}) \ge 10$ for stricter rules). This ensures $\hat{p}$ is approximately normally distributed by CLT. - **Test Statistic:** $Z = \frac{\hat{p} - p}{\sqrt{p(1-p)/n}}$. Since $p$ is unknown, we substitute $\hat{p}$ into the standard error: $SE(\hat{p}) = \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}$. - **$(1-\alpha)100\%$ CI:** $$ \hat{p} \pm z_{\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} $$ #### Desired Properties of Confidence Intervals - **High Confidence Level:** Closer to 100% (e.g., 95%, 99%). - **Narrow Width:** Provides a more precise estimate of the parameter. - There is a trade-off: to achieve a narrower interval for a given confidence level, a larger sample size is usually required. #### Typical Procedure for Confidence Interval Problems 1. **Identify the Parameter:** What population parameter ($\mu$ or $p$) are you constructing a CI for? 2. **Determine Sample Information:** Collect $n$, $\bar{x}$, $s$, or $\hat{p}$. 3. **Check Assumptions:** - Is $\sigma^2$ known or unknown? - Is the population normal? - Is the sample size large ($n \ge 30$) or small ($n ### Hypothesis Testing (Detailed) Hypothesis testing is a formal procedure for determining whether there is enough statistical evidence in a sample to reject a null hypothesis about a population. #### Recap: (Binary) Hypothesis Testing Problem In a hypothesis testing problem, $\Theta$ takes $m$ values, $\theta_1, \dots, \theta_m$. The goal is to select "the optimal" hypothesis $\theta^*$. In a special case that $\Theta$ only takes 2 values, e.g., 0 or 1, the problem is called **binary hypothesis testing**. #### Fundamental Concepts (Classical Statistical Terminology) - **Null Hypothesis ($H_0$):** Denote the hypothesis $\Theta = 0$ by $H_0$. It is considered as a default model, a statement about the population parameter that is assumed to be true until there is strong evidence to suggest otherwise. It often represents the "status quo" or "no effect" (e.g., $H_0: \mu = \mu_0$). In binary testing, $H_0$ means the parameter is $\theta_0$. - **Alternative Hypothesis ($H_1$ or $H_A$):** Denote the hypothesis $\Theta = 1$ by $H_1$. It is a statement that contradicts the null hypothesis. It represents what we are trying to find evidence for (e.g., $H_1: \mu \neq \mu_0$, $H_1: \mu > \mu_0$, $H_1: \mu f_X(X; H_0) / f_X(X; H_1) --> Observation X = x --> Decision Rule g(x) --> g(x) = H_0 OR g(x) = H_1 ``` #### Two Types of Errors For a particular choice of the rejection region $R$: - **Type I error (false rejection):** Reject hypothesis $H_0$ even though $H_0$ is true. (False positive) - The probability of Type I error: $\alpha(R) = P(X \in R; H_0)$ - **Type II error (false acceptance):** Accept hypothesis $H_0$ even though $H_0$ is false. (False negative) - The probability of Type II error: $\beta(R) = P(X \notin R; H_1)$ We want power to be high. #### Likelihood Ratio Suppose $X_1, \dots, X_n$ are independent with the same PDF/PMF. **Likelihood ratio:** $L(x_1, \dots, x_n) = \frac{f_X(x_1, \dots, x_n; H_1)}{f_X(x_1, \dots, x_n; H_0)}$ A general decision rule: $H_1$ is true ($\Theta = 1$), if $L(x_1, \dots, x_n) > \xi$, where $\xi > 0$ is the critical value, otherwise, $H_0$ is true ($\Theta = 0$). ##### Special Cases - **MAP-based (Bayesian perspective):** $$ \frac{f_{\Theta|X}(\theta=1|x)}{f_{\Theta|X}(\theta=0|x)} = \frac{f_X(x|\theta=1)P(\Theta=1)}{f_X(x|\theta=0)P(\Theta=0)} > 1 $$ This is equivalent to: $$ L(x) > \frac{P(\Theta=0)}{P(\Theta=1)} = \xi $$ - **MLE-based (Classical perspective):** $$ \frac{f_X(x; H_1)}{f_X(x; H_0)} > 1 $$ This corresponds to setting $\xi = 1$. In general, why allow $\xi > 1$ or $\xi \xi; H_0) = \alpha $$ 3. **Step 3:** Once the $X = x$ is observed, reject $H_0$ if $L(x) > \xi$. Note: $\alpha$ is called the **significance level**. Typical choices for $\alpha$ are 0.01, 0.05, 0.10. #### Neyman-Pearson Lemma Consider a particular choice of $\xi$ in LRT, which results in error probabilities: - Type I error: $P(L(X) > \xi; H_0) = \alpha$ - Type II error: $P(L(X) \le \xi; H_1) = \beta$ Suppose that some other test, with rejection region $R'$, achieves a smaller or equal false rejection probability: $P(X \in R'; H_0) \le \alpha$. Then, $P(X \notin R'; H_1) \ge \beta$. With strict inequality $P(X \notin R'; H_1) > \beta$ when $P(X \in R'; H_0) \theta_0$. Rejection region is in the upper tail. $\alpha$ is entirely in the upper tail. - **One-Tailed Test (Left-Tailed):** $H_0: \theta \ge \theta_0$ vs. $H_1: \theta ### Composite Hypothesis Testing A **composite hypothesis** is a hypothesis that does not specify the population parameter(s) exactly, but rather specifies a range of values for the parameter(s). - **Example:** $H_0: \mu \ge \mu_0$ or $H_1: \mu \neq \mu_0$. #### Likelihood Ratio Test (LRT) for Composite Hypotheses The Likelihood Ratio Test is a general method for constructing hypothesis tests, particularly useful for composite hypotheses. - **Generalized Likelihood Ratio:** $$ \Lambda(x) = \frac{\max_{\theta \in \Theta_0} L(\theta|x)}{\max_{\theta \in \Theta_1} L(\theta|x)} $$ where $\Theta_0$ is the parameter space under $H_0$, and $\Theta_1$ is the parameter space under $H_1$. - Often, $H_1$ is the unrestricted parameter space, so $\Theta_1 = \Theta$. - A small value of $\Lambda(x)$ indicates that the observed data is much less likely under $H_0$ than under $H_1$, leading to rejection of $H_0$. - **Decision Rule:** Reject $H_0$ if $\Lambda(x) \mu_0$ (Right-sided) - $H_0: \mu \ge \mu_0$ vs. $H_1: \mu z_{\alpha/2}$ - **p-value (Two-sided):** $2 \times P(Z > |Z_{obs}|)$ ##### T-Test for Mean (unknown $\sigma^2$) - **Hypotheses:** Same as Z-test, but use $H_0: \mu = \mu_0$ as the point hypothesis for calculation, even if $H_0$ is composite (e.g., $\mu \le \mu_0$). - **Test Statistic:** $T = \frac{\bar{X} - \mu_0}{S/\sqrt{n}}$ with $n-1$ degrees of freedom. - **Rejection Region (Two-sided):** $|T| > t_{\alpha/2, n-1}$ - **p-value (Two-sided):** $2 \times P(T > |T_{obs}|)$ #### Equivalence of Confidence Intervals and Hypothesis Tests - A $(1-\alpha)100\%$ confidence interval for a parameter $\theta$ can be used to perform a two-sided hypothesis test for $H_0: \theta = \theta_0$ at significance level $\alpha$. - **Rule:** If the hypothesized value $\theta_0$ falls within the $(1-\alpha)100\%$ confidence interval, then we fail to reject $H_0$. If $\theta_0$ falls outside the interval, we reject $H_0$. - This equivalence holds for two-sided tests. For one-sided tests, a one-sided confidence bound is needed. #### Typical Procedure for Composite Hypothesis Testing Problems 1. **Formulate Hypotheses:** Clearly state $H_0$ and $H_1$ (e.g., $H_0: \mu = 50$ vs. $H_1: \mu > 50$). 2. **Select Significance Level ($\alpha$):** Common choices are 0.05 or 0.01. 3. **Identify Test Statistic:** Determine if it's a Z-test (known $\sigma^2$ or large sample) or T-test (unknown $\sigma^2$ and small sample from normal population). 4. **Calculate Test Statistic:** Compute the observed value of the chosen test statistic using your sample data. 5. **Determine Critical Value(s) or p-value:** - **Critical Value Approach:** Find the critical value(s) from the Z-table or T-table based on $\alpha$ and degrees of freedom (if applicable) and whether it's a one- or two-tailed test. - **p-value Approach:** Calculate the p-value associated with your observed test statistic. 6. **Make a Decision:** - **Critical Value Approach:** Compare your observed test statistic to the critical value(s). If it falls in the rejection region, reject $H_0$. - **p-value Approach:** Compare the p-value to $\alpha$. If $p \le \alpha$, reject $H_0$. 7. **State Conclusion:** Provide a clear conclusion in the context of the problem, indicating whether there is sufficient evidence to reject $H_0$ in favor of $H_1$. ### Comparing Populations Often, the goal is to compare parameters (e.g., means, proportions) from two or more different populations. #### Comparing Two Population Means ($\mu_1, \mu_2$) ##### Case 1: Independent Samples, Population Variances KNOWN ($\sigma_1^2, \sigma_2^2$ known) - **Assumptions:** - Two independent random samples from two populations. - Populations are normal OR sample sizes $n_1, n_2$ are large (CLT applies). - $\sigma_1^2, \sigma_2^2$ are known. - **Hypotheses:** $H_0: \mu_1 - \mu_2 = D_0$ (often $D_0=0$) vs. $H_1: \mu_1 - \mu_2 \neq D_0$ (or one-sided). - **Test Statistic:** $$ Z = \frac{(\bar{X}_1 - \bar{X}_2) - D_0}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}} \sim \mathcal{N}(0,1) $$ - **Confidence Interval for $\mu_1 - \mu_2$:** $$ (\bar{x}_1 - \bar{x}_2) \pm z_{\alpha/2} \sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}} $$ ##### Case 2: Independent Samples, Population Variances UNKNOWN - **Subcase 2a: Large Sample Sizes ($n_1 \ge 30, n_2 \ge 30$)** - **Assumptions:** Same as Case 1, but $\sigma_1^2, \sigma_2^2$ are unknown. - Use sample variances $s_1^2, s_2^2$ as estimates for $\sigma_1^2, \sigma_2^2$. - **Test Statistic (approximate):** $$ Z \approx \frac{(\bar{X}_1 - \bar{X}_2) - D_0}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}} \sim \mathcal{N}(0,1) $$ - **Confidence Interval for $\mu_1 - \mu_2$:** $$ (\bar{x}_1 - \bar{x}_2) \pm z_{\alpha/2} \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}} $$ - **Subcase 2b: Small Sample Sizes ($n_1